Aprendizaje Supervisado: Fundamentos y Conceptos Clave
Definición de Aprendizaje Supervisado
El aprendizaje supervisado es un paradigma fundamental del machine learning donde un algoritmo aprende a mapear datos de entrada a salidas específicas basándose en ejemplos de pares entrada-salida. Este tipo de aprendizaje utiliza conjuntos de datos etiquetados, donde cada elemento de datos de entrada tiene una salida correcta correspondiente, para entrenar modelos estadísticos que puedan hacer predicciones precisas en datos nuevos y no vistos.
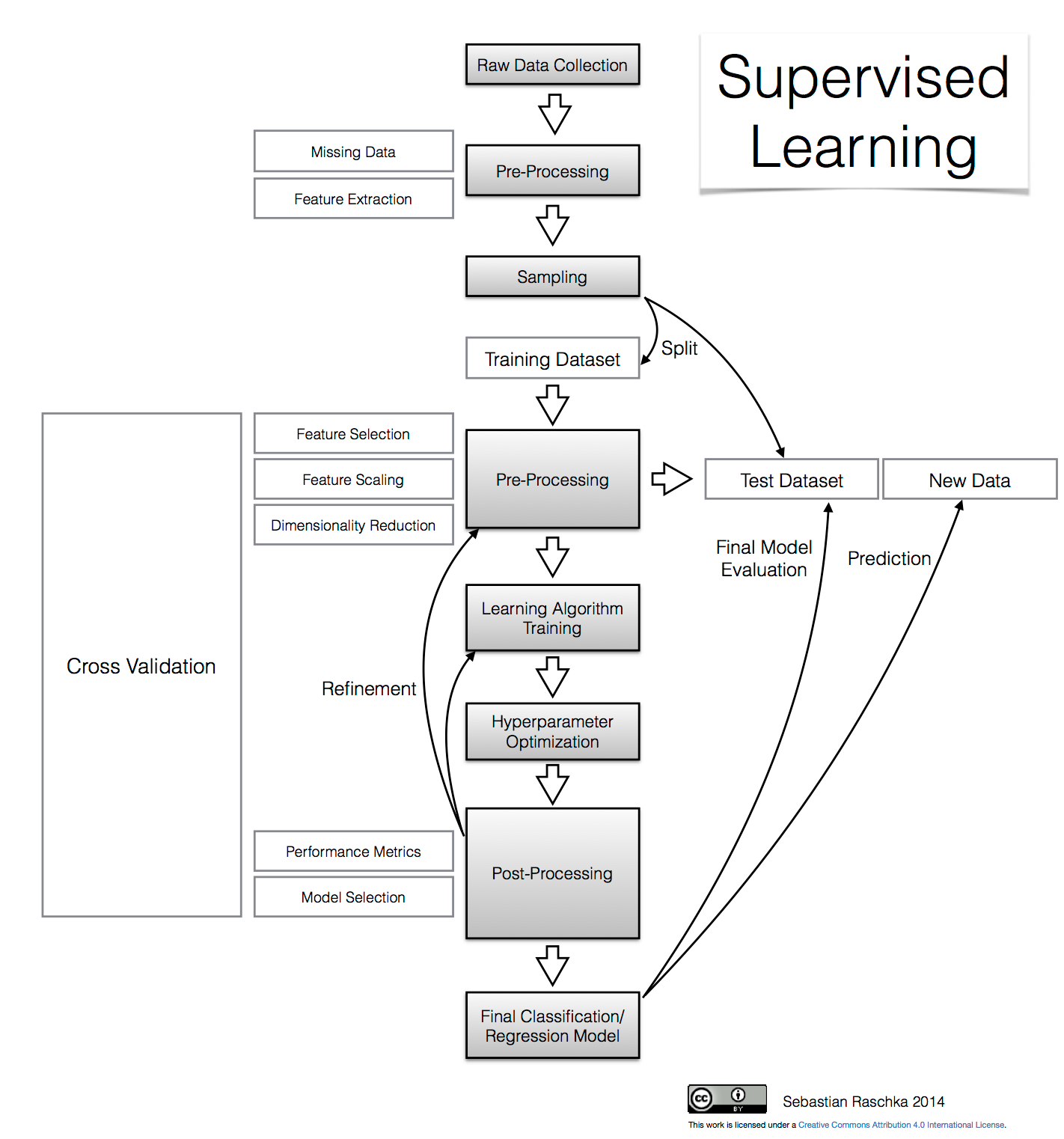
Flowchart diagram illustrating the supervised learning workflow, from data collection to model evaluation and prediction.
El proceso funciona mediante reconocimiento de patrones: al analizar un conjunto específico de datos etiquetados, un algoritmo puede detectar patrones y generar predicciones basadas en esos patrones derivados cuando se consulta. La calidad de la salida está directamente relacionada con la calidad de los datos: mejores datos significan mejores predicciones.
Características Principales del Aprendizaje Supervisado
- Datos Etiquetados: Requiere conjuntos de datos donde cada entrada tiene una salida conocida y correcta
- Aprendizaje Guiado: El algoritmo recibe retroalimentación explícita sobre la corrección de sus predicciones
- Generalización: El objetivo es que el modelo entrenado pueda predecir con precisión la salida para datos nuevos y no vistos
- Evaluación Objetiva: El rendimiento se puede medir comparando las predicciones con las etiquetas conocidas
Tipos de Problemas: Clasificación vs Regresión
El aprendizaje supervisado se divide principalmente en dos tipos de problemas según la naturaleza de la variable objetivo:
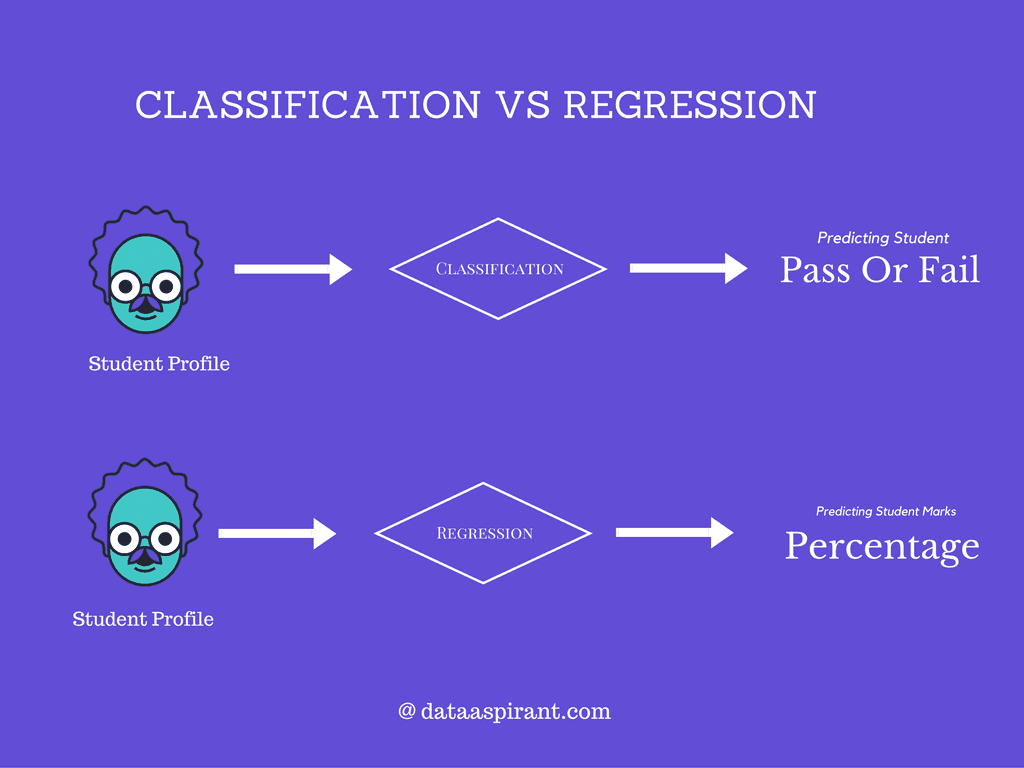
Visual comparison of classification and regression in supervised learning showing categorical output prediction (pass/fail) versus continuous output prediction (percentage).
Clasificación
La clasificación es un tipo de problema supervisado donde el objetivo es predecir categorías o clases discretas. El algoritmo aprende a asignar datos de entrada a categorías predefinidas basándose en características compartidas.
Características de la Clasificación:
- Variable de salida: Valores discretos o categóricos
- Objetivo: Encontrar límites de decisión que separen las clases
- Ejemplos: Detección de spam (spam/no spam), diagnóstico médico (enfermedad/sin enfermedad), reconocimiento de imágenes (gato/perro)
Tipos de Clasificación:
- Clasificación Binaria: Categoriza datos en una de dos categorías (ejemplo: aprobar/reprobar)
- Clasificación Multiclase: Maneja múltiples categorías (ejemplo: clasificar tipos de animales)
- Clasificación Multilabel: Permite múltiples etiquetas para una sola instancia
Regresión
La regresión encuentra correlaciones entre variables dependientes e independientes, prediciendo valores continuos. Los algoritmos de regresión ayudan a predecir variables continuas como precios de casas, tendencias de mercado, patrones climáticos, etc.
Características de la Regresión:
- Variable de salida: Valores continuos o reales
- Objetivo: Encontrar la línea de mejor ajuste que prediga la salida con mayor precisión
- Ejemplos: Predicción de precios de viviendas, pronóstico de temperaturas, estimación de ventas
Tipos de Regresión:
- Regresión Lineal Simple: Modela la relación entre una variable independiente y una dependiente
- Regresión Lineal Múltiple: Predice una variable dependiente basada en dos o más variables independientes
- Regresión Polinomial: Modela relaciones no lineales ajustando una curva a los datos
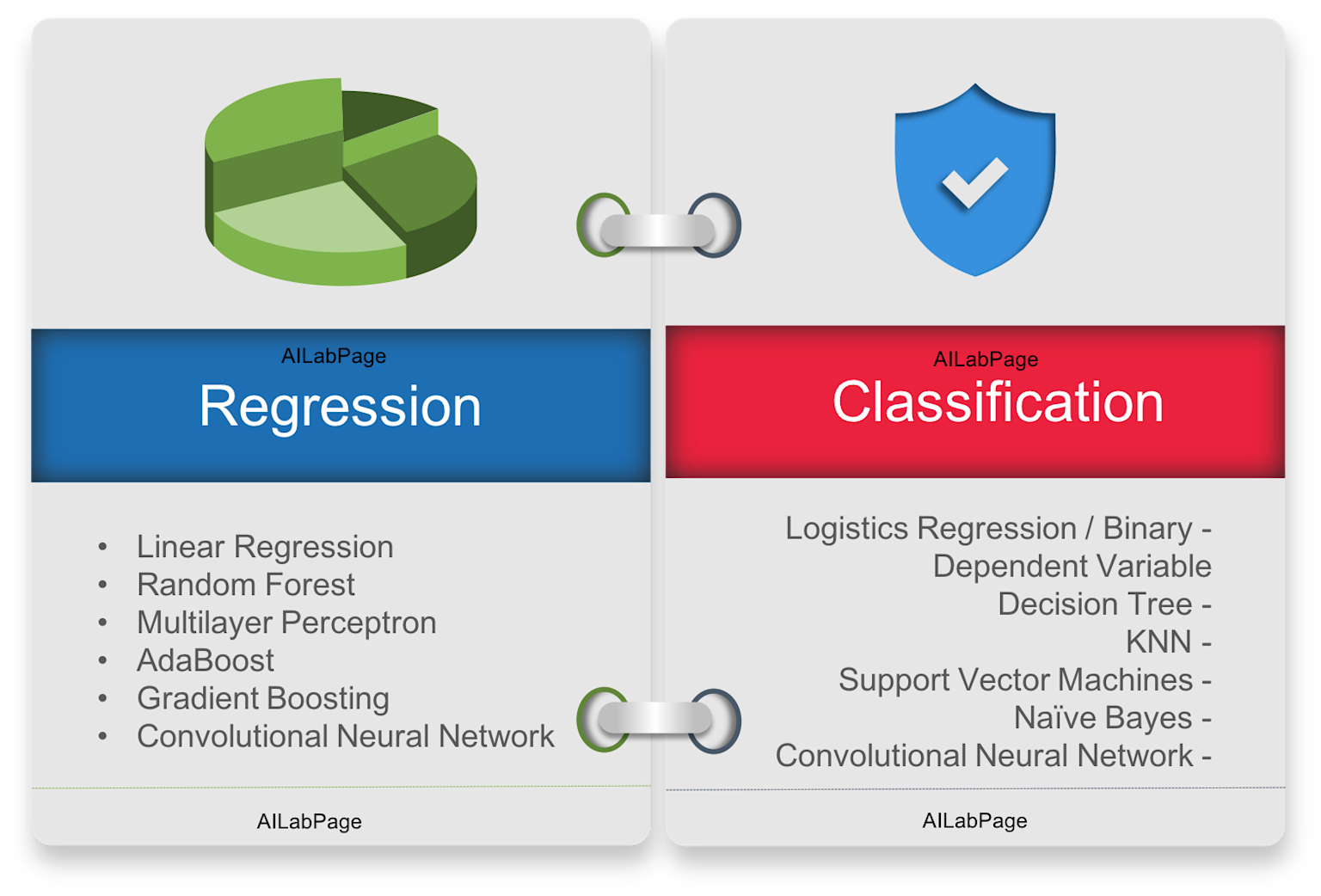
Comparison of regression and classification problems with examples of common machine learning algorithms for each type.
Diferencias Clave entre Clasificación y Regresión
| Aspecto | Clasificación | Regresión |
|---|---|---|
| Tipo de salida | Valores discretos/categóricos | Valores continuos/reales |
| Objetivo | Encontrar límites de decisión | Encontrar línea de mejor ajuste |
| Tipo de datos | Datos discretos | Datos continuos |
| Ejemplos típicos | Detección spam, diagnóstico médico | Predicción precios, pronóstico clima |
| Métricas de evaluación | Precisión, recall, F1-score | MAE, MSE, RMSE |
Jerarquía: Inteligencia Artificial → Machine Learning → Deep Learning
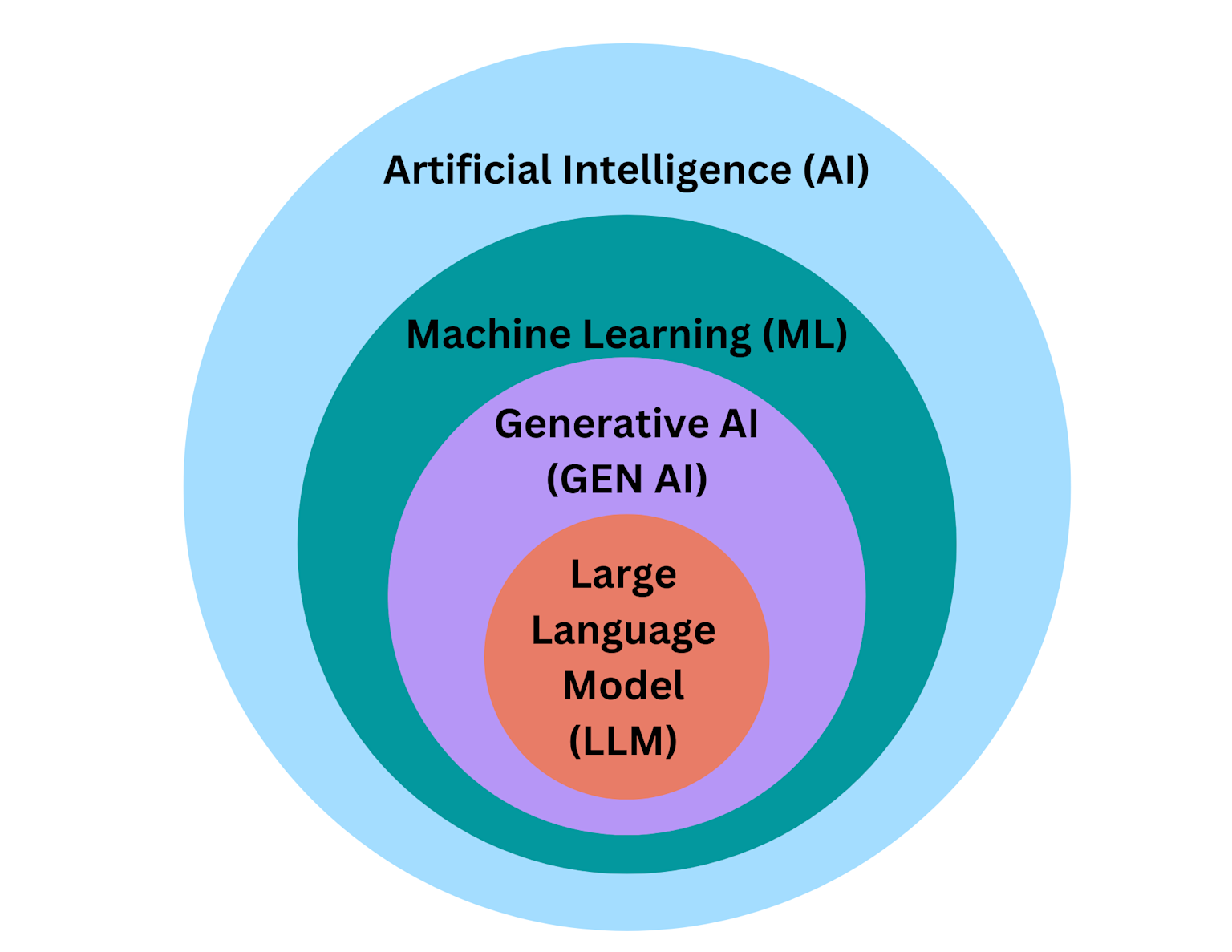
Hierarchical diagram showing how artificial intelligence includes machine learning, which includes generative AI, and further includes large language models.
La relación entre estos campos forma una jerarquía clara donde cada área es un subconjunto de la anterior:
Inteligencia Artificial (IA)
La Inteligencia Artificial representa el concepto más amplio, dedicado a crear sistemas o máquinas que puedan realizar tareas que típicamente requieren inteligencia humana. Incluye razonamiento, resolución de problemas, aprendizaje y percepción.
Características de la IA:
- Alcance: El más amplio de los tres conceptos
- Objetivo: Simular o replicar la inteligencia humana en máquinas
- Enfoques: Puede usar lógica, sistemas basados en reglas, algoritmos de búsqueda, optimización, y especialmente machine learning y deep learning
Machine Learning (ML)
El Machine Learning es un subconjunto de la IA que se enfoca en desarrollar sistemas que pueden aprender de datos y tomar decisiones basadas en ellos, sin ser programados explícitamente para cada escenario.
Características del ML:
- Relación: Subconjunto de la IA
- Objetivo: Permitir que las máquinas aprendan de los datos para realizar tareas específicas con precisión
- Enfoques: Usa algoritmos como regresión lineal, SVM, árboles de decisión, random forests
- Requerimientos de datos: Moderados comparado con deep learning
Deep Learning (DL)
El Deep Learning es un subconjunto especializado del machine learning que utiliza redes neuronales artificiales multicapa para aprender patrones complejos y representaciones jerárquicas directamente de grandes cantidades de datos sin procesar.
Características del Deep Learning:
- Relación: Subconjunto del ML, que a su vez es subconjunto de la IA
- Objetivo: Lograr mayor precisión y manejar patrones más complejos aprendiendo características automáticamente
- Estructura: Usa redes neuronales complejas multicapa inspiradas en la estructura del cerebro humano
- Requerimientos: Demanda recursos computacionales significativos y grandes cantidades de datos
Diferencias entre los Niveles
| Aspecto | IA | Machine Learning | Deep Learning |
|---|---|---|---|
| Alcance | Más amplio | Subconjunto de IA | Subconjunto de ML |
| Complejidad | Variable | Moderada | Alta |
| Requerimientos de datos | Variable | Moderados | Grandes cantidades |
| Intervención humana | Variable | Moderada | Mínima |
| Tiempo de entrenamiento | Variable | Moderado | Extenso |
Metodología: División Temporal de Datos
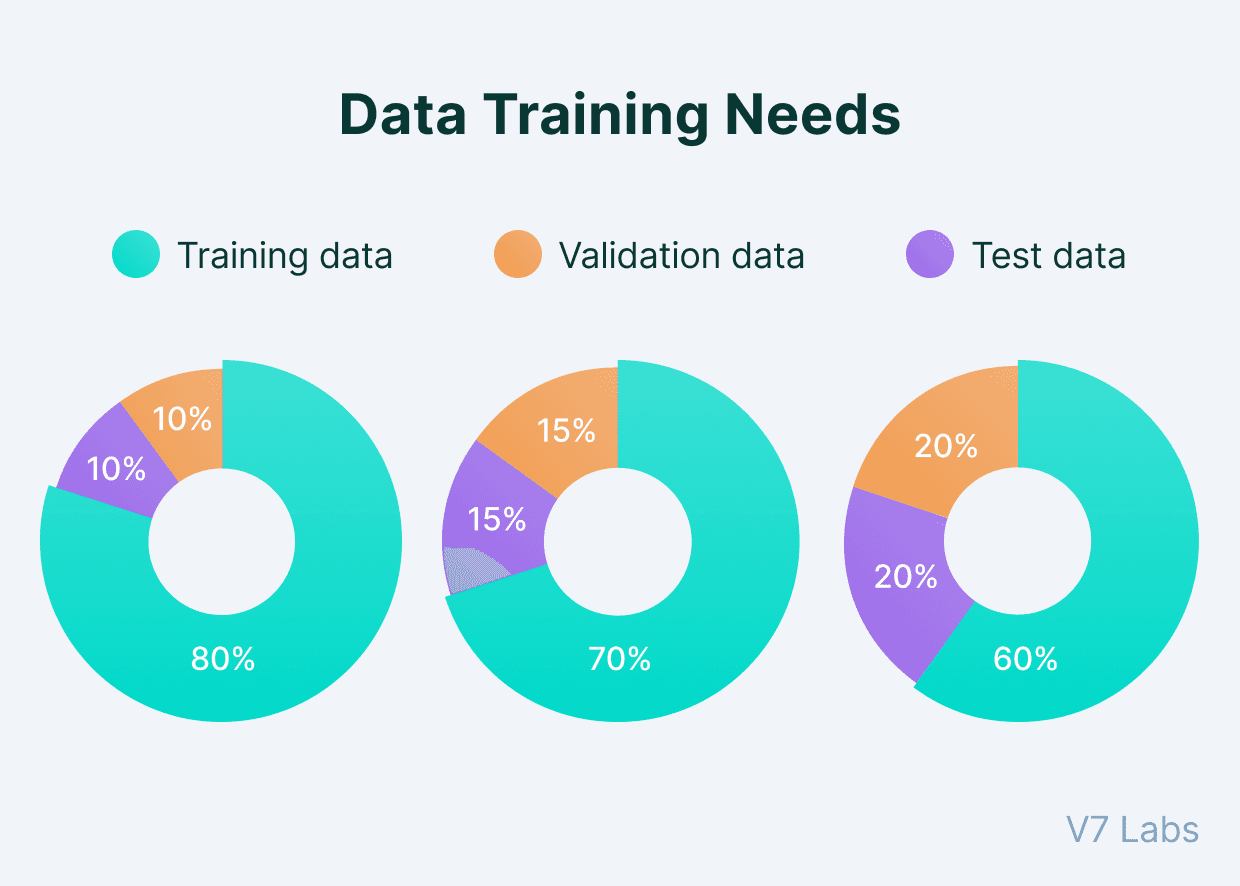
Examples of data splits into training, validation, and test sets with varying proportions in machine learning workflows.
La división temporal de datos es una metodología fundamental en el aprendizaje supervisado que separa los datos en conjuntos distintos para entrenar, validar y probar modelos de manera efectiva.
Propósito de Cada Conjunto
Conjunto de Entrenamiento (Training Set):
- Función: Utilizado para ajustar el modelo y donde el modelo aprende los patrones subyacentes en los datos
- Características: Debe tener un conjunto diversificado de entradas para que el modelo se entrene en todos los escenarios
- Proporción típica: 60-80% de los datos totales
Conjunto de Validación (Validation Set):
- Función: Usado para ajustar hiperparámetros y selección del modelo durante el entrenamiento
- Objetivo: Prevenir el sobreajuste y proporcionar información para ajustar configuraciones
- Proporción típica: 10-20% de los datos totales
Conjunto de Prueba (Test Set):
- Función: Proporciona una evaluación imparcial del rendimiento final del modelo
- Importancia: Debe permanecer intocado hasta la fase de evaluación final
- Proporción típica: 10-20% de los datos totales
División Temporal vs División Aleatoria
División Temporal
La división temporal es especialmente importante cuando los datos tienen naturaleza temporal:
Ventajas:
- Realismo: Simula condiciones de uso real donde el modelo predice el futuro
- Prevención de data leakage: Evita que información futura contamine el entrenamiento
- Validación prospectiva: Proporciona estimaciones más precisas de la calidad predictiva
Cuándo usar:
- Datos de series temporales
- Cuando el orden temporal es relevante
- Para simular despliegue en producción
División Aleatoria
Limitaciones:
- Puede crear solapamiento temporal entre conjuntos de entrenamiento y prueba
- No refleja condiciones realistas de uso
- Puede llevar a estimaciones optimistas de rendimiento
Mejores Prácticas para División de Datos
Proporciones Recomendadas:
- Estándar: 70% entrenamiento, 15% validación, 15% prueba
- Datasets grandes: 80% entrenamiento, 10% validación, 10% prueba
- Datasets pequeños: Considerar validación cruzada para eficiencia
Consideraciones Especiales:
- Muestreo representativo: Asegurar que cada conjunto refleje la distribución de la población
- Datos balanceados: Mantener proporciones similares de clases en cada conjunto
- Calidad de datos: Aplicar las mismas técnicas de preprocesamiento a todos los conjuntos
Ejemplos de Código
División Básica con Scikit-learn
from sklearn.model_selection import train_test_split
import pandas as pd
# Cargar datos
data = pd.read_csv('datos.csv')
X = data.drop('target', axis=1)
y = data['target']
# División en entrenamiento y prueba (80-20)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# División adicional para validación (60-20-20)
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train, test_size=0.25, random_state=42, stratify=y_train
)División Temporal para Series de Tiempo
import pandas as pd
from sklearn.model_selection import TimeSeriesSplit
# Para datos temporales
def temporal_split(data, train_ratio=0.6, val_ratio=0.2):
n = len(data)
train_end = int(n * train_ratio)
val_end = int(n * (train_ratio + val_ratio))
train_data = data[:train_end]
val_data = data[train_end:val_end]
test_data = data[val_end:]
return train_data, val_data, test_data
# Validación cruzada temporal
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]Algoritmos Comunes de Aprendizaje Supervisado
Algoritmos de Clasificación
Regresión Logística:
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Entrenar modelo
model = LogisticRegression(random_state=42)
model.fit(X_train, y_train)
# Predicción y evaluación
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Precisión: {accuracy:.3f}")
print(classification_report(y_test, y_pred))Árbol de Decisión:
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import confusion_matrix
# Entrenar modelo
dt = DecisionTreeClassifier(max_depth=5, random_state=42)
dt.fit(X_train, y_train)
# Evaluación
y_pred = dt.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
print("Matriz de confusión:")
print(cm)Algoritmos de Regresión
Regresión Lineal:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import numpy as np
# Entrenar modelo
lr = LinearRegression()
lr.fit(X_train, y_train)
# Predicción y evaluación
y_pred = lr.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print(f"RMSE: {rmse:.3f}")
print(f"R²: {r2:.3f}")Métricas de Evaluación
Para Clasificación
- Precisión (Accuracy): Proporción de predicciones correctas
- Precision: TP/(TP+FP) - útil cuando los falsos positivos son costosos
- Recall (Sensibilidad): TP/(TP+FN) - importante cuando perder un positivo es peor
- F1-Score: Media armónica de precision y recall
- AUC-ROC: Mide la capacidad del modelo para distinguir entre clases
Para Regresión
- MAE (Error Absoluto Medio): Promedio de las diferencias absolutas
- MSE (Error Cuadrático Medio): Penaliza más los errores grandes
- RMSE: Raíz cuadrada del MSE, en las mismas unidades que el objetivo
- R² (Coeficiente de Determinación): Explica la varianza capturada por el modelo
El aprendizaje supervisado representa la base fundamental del machine learning moderno, proporcionando las herramientas y metodologías necesarias para resolver una amplia gama de problemas predictivos en diversos dominios. La comprensión de estos conceptos fundamentales es esencial para cualquier aplicación exitosa de técnicas de inteligencia artificial.

Hi :)
Matemáticas
Vectores
Álgebra Lineal
Geometría Analítica
Producto Punto
Espacios Vectoriales
Ortogonalidad
Normalización
Funciones
Álgebra
Composición de Funciones
Función Inversa
Combinación de Funciones
Transformaciones Gráficas
Aplicaciones Económicas
Interés Compuesto
Proporcionalidad
R
Data
Machine Learning
Aprendizaje Supervisado
Inteligencia Artificial
Clasificación
Regresión
Deep Learning